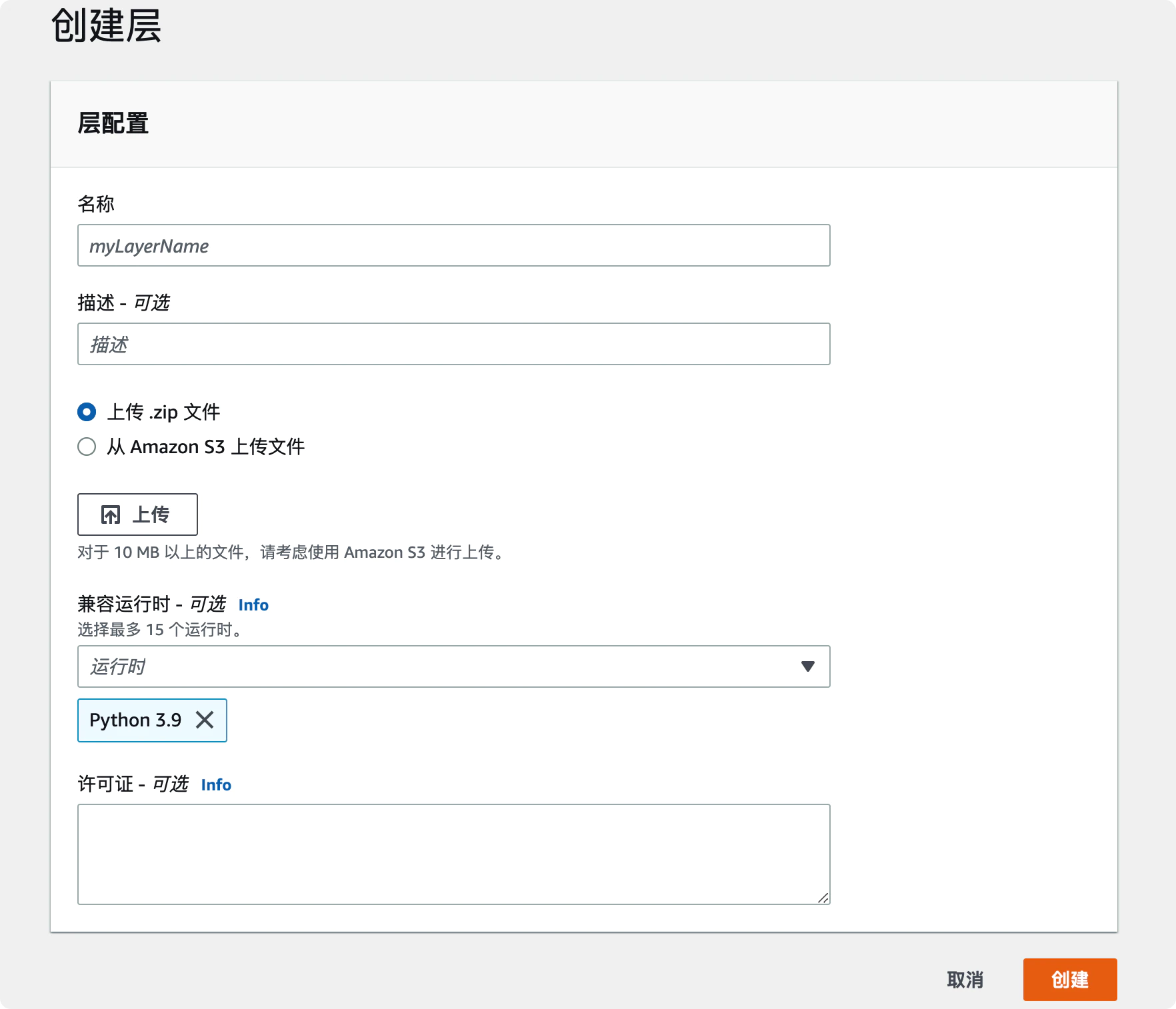
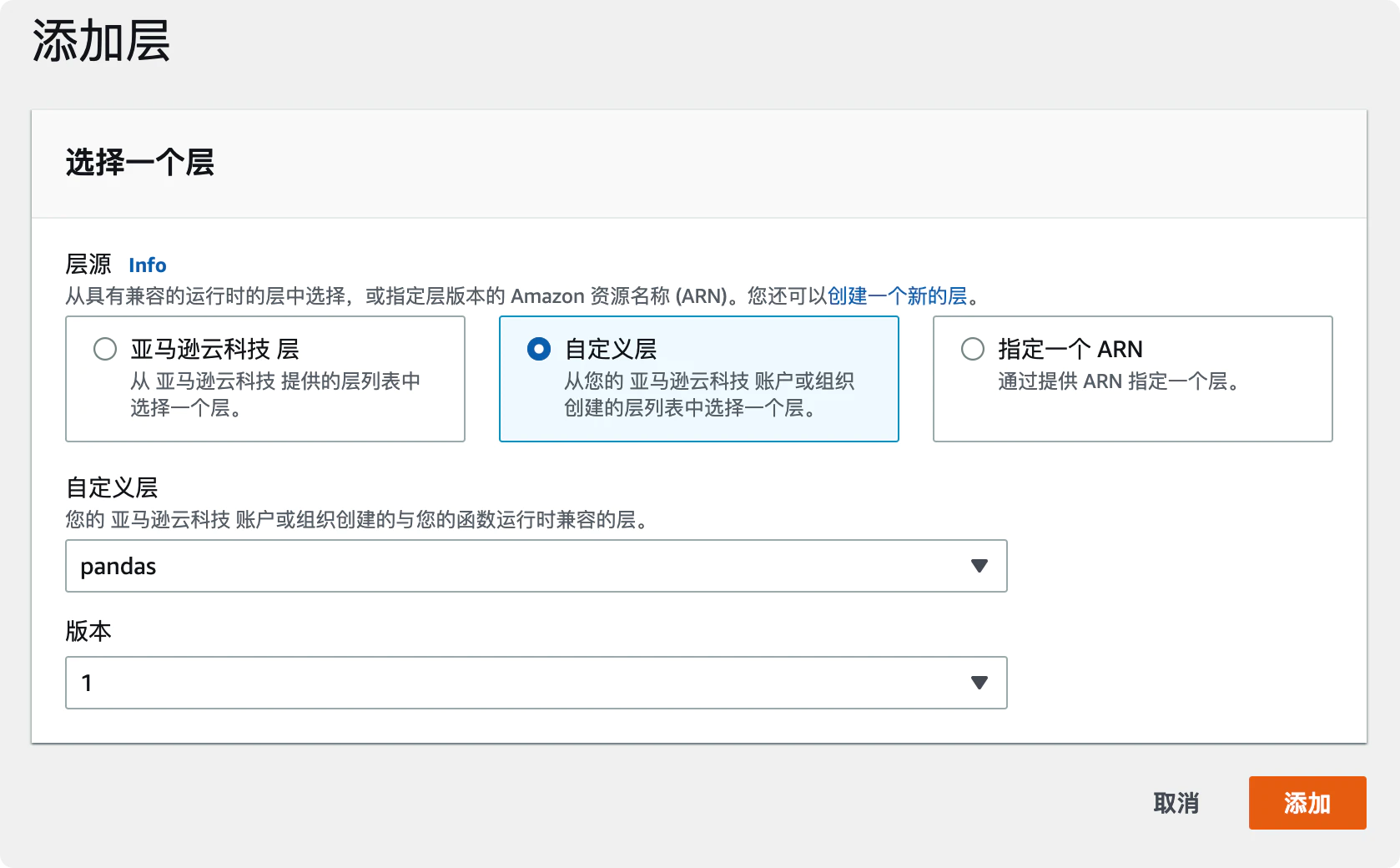
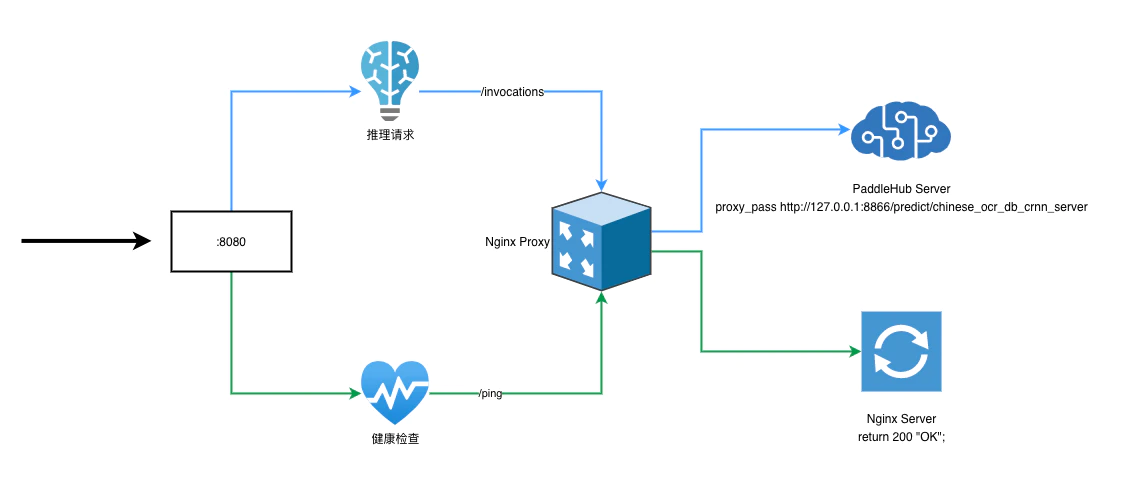
旧的 ClickHouse 服务部署在 AWS EKS 集群中,与其他服务共享资源,现迁移到独立的 EC2 机器上,独享资源。考虑成本,新的机器使用 arm 处理器。
使用到的工具是 clickhouse-backup。
备份原服务数据
使用 clickhouse-backup 备份原服务数据到 S3,备份 example_schema schema 下的所有表到 S3 的命令如下:
./clickhouse-backup create_remote -c clickhouse-backup-config.yml -t [example_schema].*此操作会把 example_schema 下的表结构以及数据备份到 S3 的目录,S3 的相关配置在 clickhouse-backup-config.yml 里面。
备份后会在 S3 生成以备份时间命名的文件夹:
这个文件夹的名字作为备份的名字会在恢复数据的时候使用。
在新服务上恢复数据
使用原服务同样的 clickhouse-backup-config.yml 配置,把数据库相关配置换成新服务的:
clickhouse:
username: username
password: "password"
host: localhost
port: 9000
disk_mapping: {}
skip_tables:
- system.*
timeout: 5m
freeze_by_part: false
secure: false
skip_verify: false
sync_replicated_tables: true
skip_sync_replica_timeouts: true
log_sql_queries: false之后,执行恢复数据的命令:
./clickhouse-backup restore_remote -c clickhouse-backup-config.yml 2023-03-24T01-46-40等待命令执行完毕,数据即可恢复成功。
Clickhouse 安装
使用 install.sh 安装脚本,代码如下,LATEST_VERSION 写死想要安装的版本,否则会根据服务器信息安装最新的版本。install.sh 脚本代码如下:
LATEST_VERSION=22.3.6.5-arm64
export LATEST_VERSION
case $(uname -m) in
x86_64) ARCH=amd64 ;;
aarch64) ARCH=arm64 ;;
*) echo "Unknown architecture $(uname -m)"; exit 1 ;;
esac
for PKG in clickhouse-common-static clickhouse-common-static-dbg clickhouse-server clickhouse-client clickhouse-keeper
do
curl -fO "https://packages.clickhouse.com/tgz/stable/$PKG-$LATEST_VERSION-${ARCH}.tgz" \
|| curl -fO "https://packages.clickhouse.com/tgz/stable/$PKG-$LATEST_VERSION.tgz"
done
tar -xzvf "clickhouse-common-static-$LATEST_VERSION-${ARCH}.tgz" \
|| tar -xzvf "clickhouse-common-static-$LATEST_VERSION.tgz"
sudo "clickhouse-common-static-$LATEST_VERSION/install/doinst.sh"
tar -xzvf "clickhouse-common-static-dbg-$LATEST_VERSION-${ARCH}.tgz" \
|| tar -xzvf "clickhouse-common-static-dbg-$LATEST_VERSION.tgz"
sudo "clickhouse-common-static-dbg-$LATEST_VERSION/install/doinst.sh"
tar -xzvf "clickhouse-server-$LATEST_VERSION-${ARCH}.tgz" \
|| tar -xzvf "clickhouse-server-$LATEST_VERSION.tgz"
sudo "clickhouse-server-$LATEST_VERSION/install/doinst.sh" configure
sudo /etc/init.d/clickhouse-server start
tar -xzvf "clickhouse-client-$LATEST_VERSION-${ARCH}.tgz" \
|| tar -xzvf "clickhouse-client-$LATEST_VERSION.tgz"
sudo "clickhouse-client-$LATEST_VERSION/install/doinst.sh"