// 命令式编程做法let res = false;
for(i = 0; i < dataArr.length; i++) {
if (i === 3) {
res = true;
}
}
console.log(res);
// 声明式编程做法let res = dataArr.filter(i => i === 3);
console.log(res);
<?php
namespace App\Events;
use Illuminate\Broadcasting\InteractsWithSockets;
use Illuminate\Foundation\Events\Dispatchable;
use Illuminate\Queue\SerializesModels;
class PublishArticle {
use Dispatchable, InteractsWithSockets, SerializesModels;
/**
* Create a new event instance.*
* @return void
*/
public function __construct()
{
//
}
/**
* Get the channels the event should broadcast on.
* @return \Illuminate\Broadcasting\Channel|array
*/
public function broadcastOn()
{
return [];
}
}
GenSiteMapListener.php
<?php
namespace App\Listeners;
use App\Article;
use App\Events\PublishArticle;
use Carbon\Carbon;
use Illuminate\Contracts\Queue\ShouldQueue;
use Spatie\Sitemap\Sitemap;
use Spatie\Sitemap\Tags\Url;
class GenSiteMapListener implements ShouldQueue {
/**
* Create the event listener.*
* @return void
*/
public function __construct()
{
//
}
/**
* Handle the event.
* @param PublishArticle $event
* @return void
*/
public function handle(PublishArticle $event)
{
$publicPath = public_path('sitemap.xml');
$siteMap = Sitemap::create();
$siteMap
->add(Url::create(action('HomeController@index'))
->setLastModificationDate(Carbon::yesterday())
->setChangeFrequency(\Spatie\Sitemap\Tags\Url::CHANGE_FREQUENCY_DAILY)
->setPriority(0.1))
->add(Url::create(action('ArticlesController@index'))
->setLastModificationDate(Carbon::yesterday())
->setChangeFrequency(\Spatie\Sitemap\Tags\Url::CHANGE_FREQUENCY_MONTHLY)
->setPriority(0.1));
Article::all()->each(function ($article) use ($siteMap) {
if ($article->status === 1) {
$siteMap->add(Url::create(action('ArticlesController@show', [$article->id]))
->setLastModificationDate($article->updated_at)
->setChangeFrequency(\Spatie\Sitemap\Tags\Url::CHANGE_FREQUENCY_MONTHLY)
->setPriority(0.2));
}
});
$siteMap->writeToFile($publicPath);
$siteMap = null;
}
}
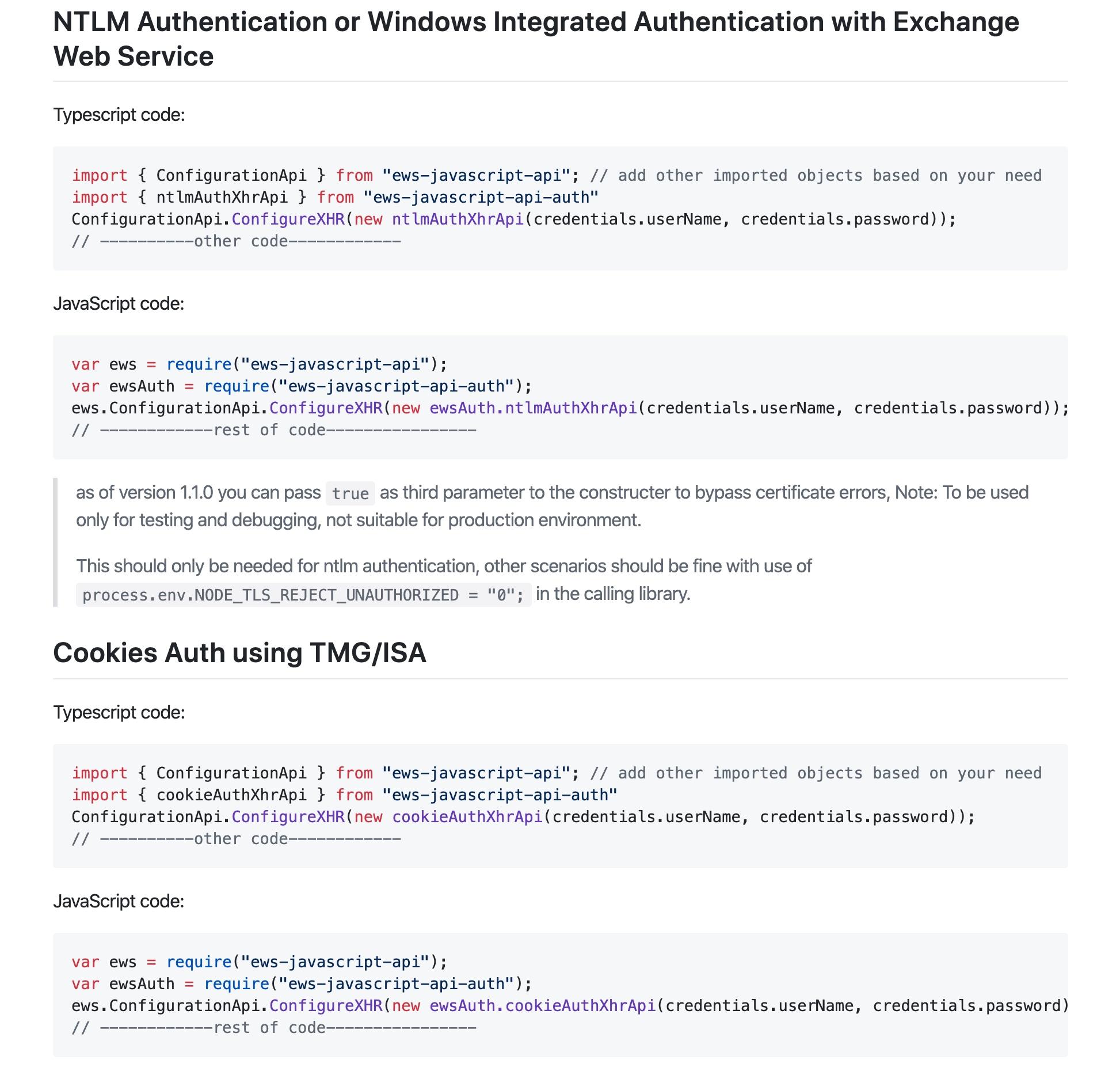
import {
ExchangeService, ExchangeVersion,
Uri as ExchangeUri,
WebCredentials, EmailMessage, MessageBody, ConfigurationApi
} from 'ews-javascript-api';
2. 新建ExchangeService 服务
const exch = new ExchangeService(ExchangeVersion.Exchange2007_SP1);
3. 配置登录凭据以及服务地址
exch.Credentials = new WebCredentials(ewsConfig.username, ewsConfig.password);
exch.Url = new ExchangeUri(ewsConfig.host);
upstream jenkins {
keepalive 32; # keepalive connections
server 127.0.0.1:8080; # jenkins ip and port
}
server {
listen 80;
server_name jenkins.example.com;
#this is the jenkins web root directory (mentioned in the /etc/default/jenkins file)
root /var/run/jenkins/war/;
access_log /var/log/jenkins/access.log;
error_log /var/log/error.log;
ignore_invalid_headers off; #pass through headers from Jenkins which are considered invalid by Nginx server.
location ~ "^/static/[0-9a-fA-F]{8}\/(.*)$" {
#rewrite all static files into requests to the root
#E.g /static/12345678/css/something.css will become /css/something.css
rewrite "^/static/[0-9a-fA-F]{8}\/(.*)" /$1 last;
}
location /userContent {
#have nginx handle all the static requests to the userContent folder files
#note : This is the $JENKINS_HOME dir
root /var/lib/jenkins/;
if (!-f $request_filename){
#this file does not exist, might be a directory or a /**view** url
rewrite (.*) /$1 last;
break;
}
sendfile on;
}
location / {
sendfile off;
proxy_pass http://jenkins;
proxy_redirect default;
proxy_http_version 1.1;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_max_temp_file_size 0;
#this is the maximum upload size
client_max_body_size 10m;
client_body_buffer_size 128k;
proxy_connect_timeout 90;
proxy_send_timeout 90;
proxy_read_timeout 90;
proxy_buffering off;
proxy_request_buffering off; # Required for HTTP CLI commands in Jenkins > 2.54
proxy_set_header Connection ""; # Clear for keepalive
}
}
有人自嘲说投胎到中国,相当于开启了人生的 hard 模式。我们国人确实是比较勤劳的,近现代我们落后了,等我们回过神来后奋起直追,迅速缩小了与世界强国的差距。目前,我们与西方先进国家,在科技等领域的核心技术层面,还是存在差距。这些领域的差距通过延长工作时间来追赶,效果不会好。对于上班族来说,也会遇到很多问题不是通过加班就能解决的。
工作价值、产出与成就感的获得
16年的一篇报道《中国劳动生产率增速远超世界平均水平 仍有提升空间》提到:2015年我国劳动生产率水平仅为世界平均水平的40%,相当于美国劳动生产率的7.4%!这也意味着单位劳动时间里,我们创造出的价值太低了。美国民众是比较重视家庭生活的,5点下班后就回家了。这样的生活工作节奏,美国每年 GDP 依旧是世界第一。原因是美国人超高的劳动生产率。












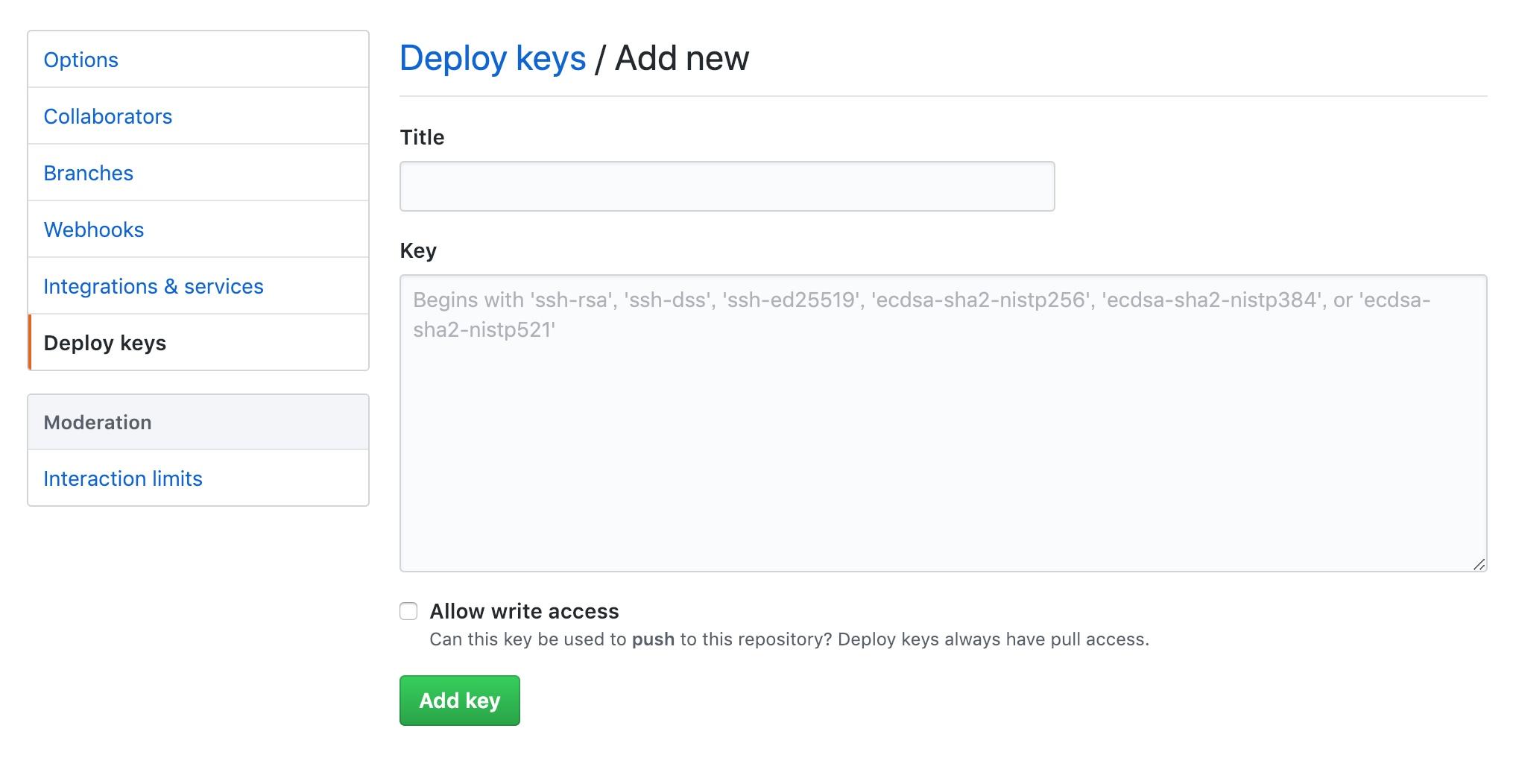
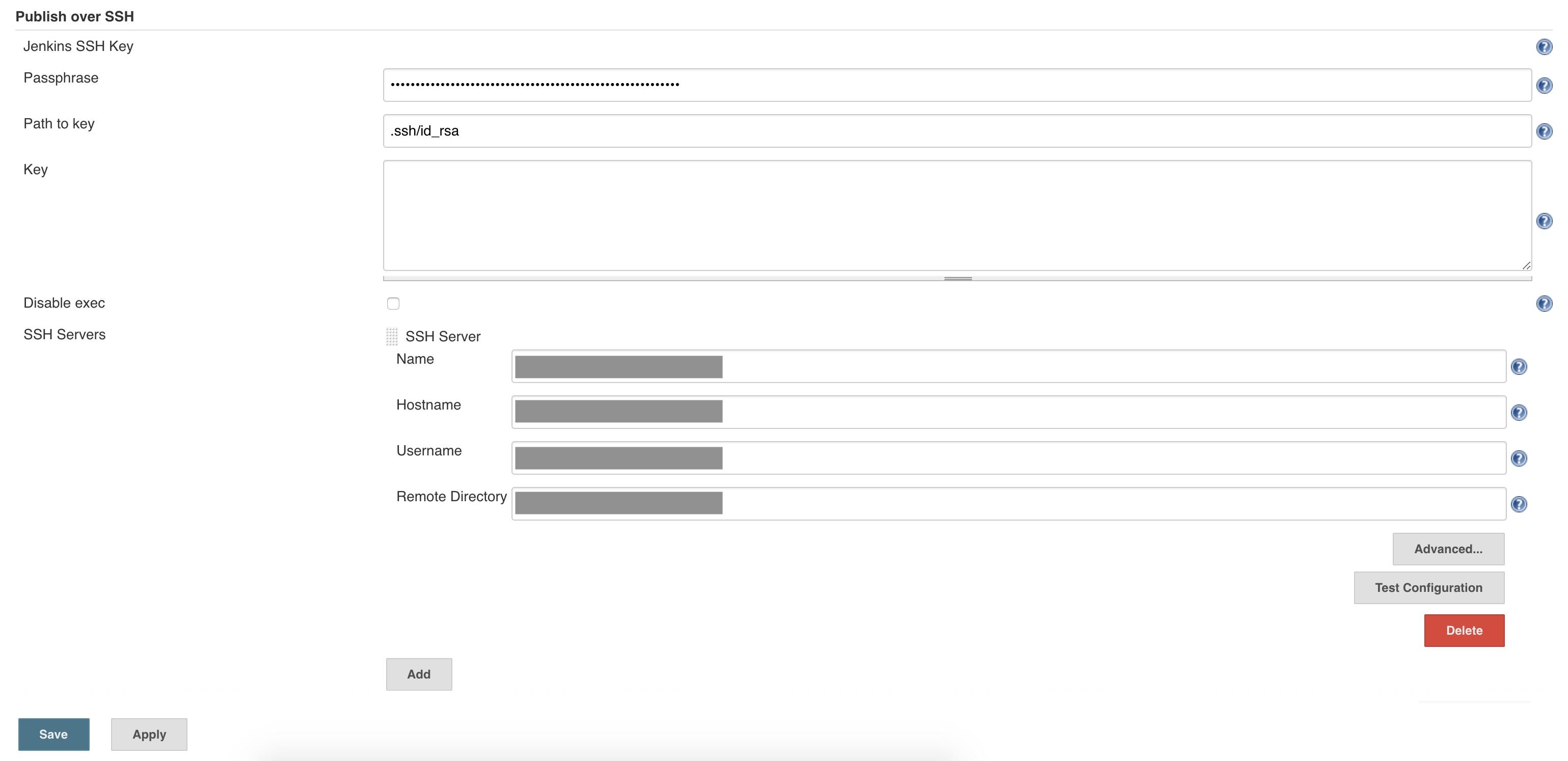
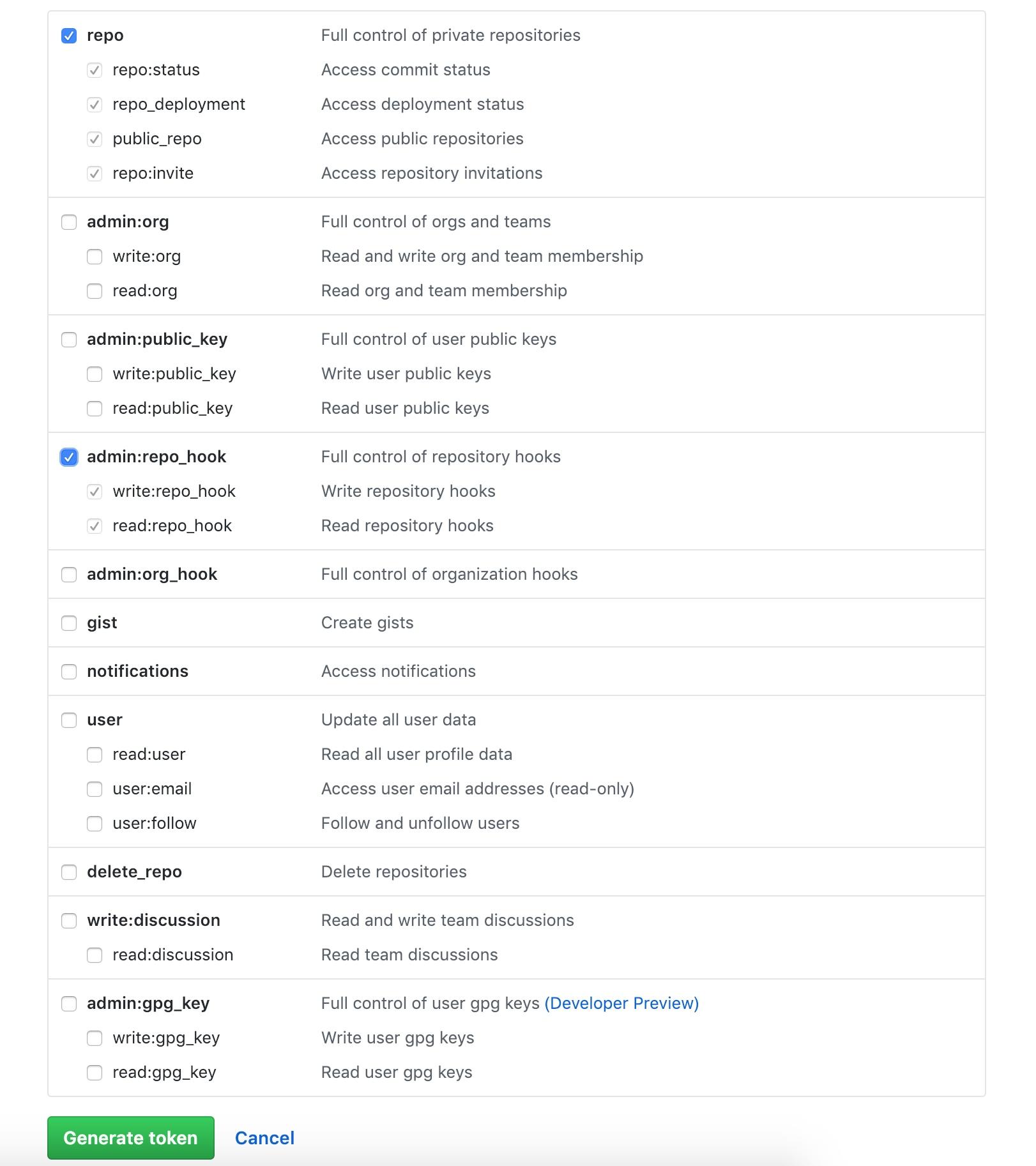
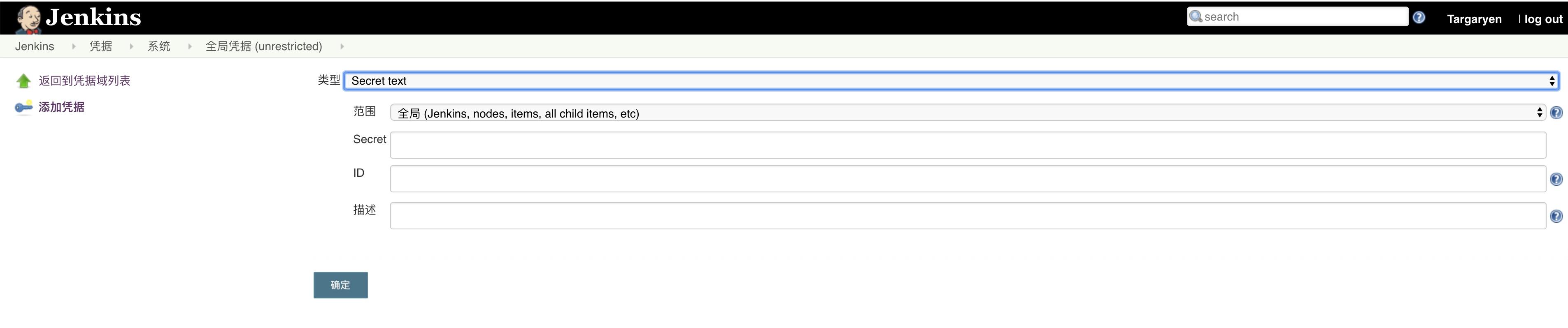
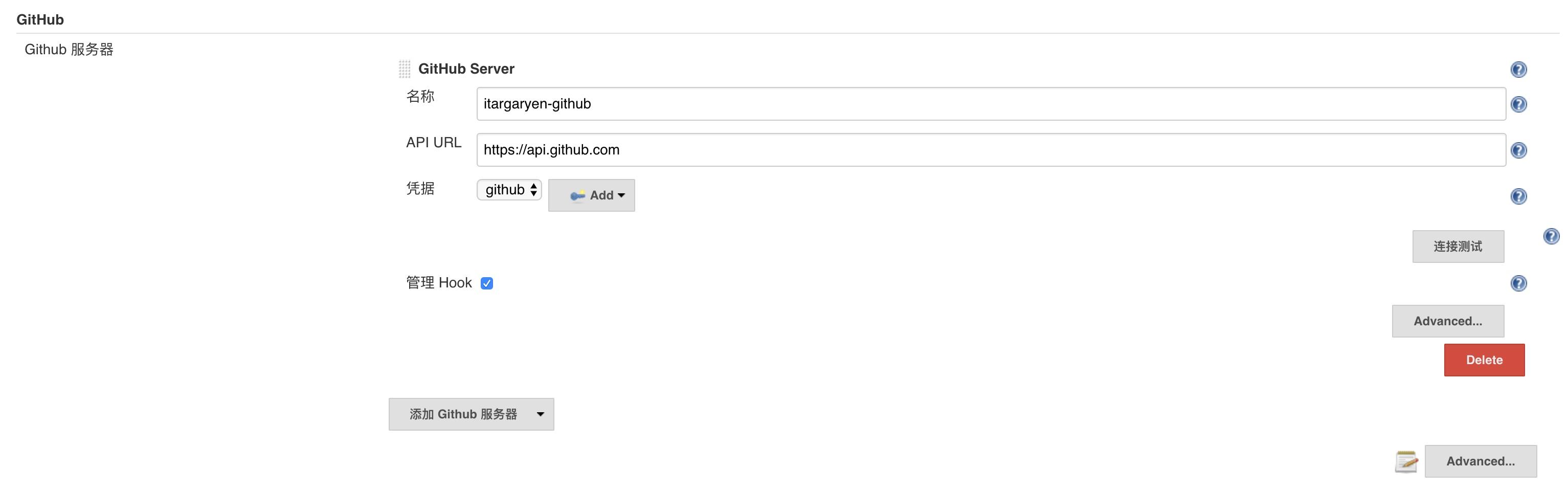 凭据选择刚才添加的那个,这里是 github。保存配置,凭据添加完成。
凭据选择刚才添加的那个,这里是 github。保存配置,凭据添加完成。