需要用到的硬件
烧录好系统的树莓派主机,我使用的是 Raspberry Pi 3B,系统使用RASPBIAN JESSIE LITE;
树莓派适用的散热外壳(大量上传下载的情况下,系统发热量惊人,推荐配置);
硬盘 + 硬盘底座(树莓派的供电是带不起移动硬盘的,即便给移动硬盘额外的 USB 供电也吃力,强烈推荐)。

我买的 3B 及其外壳,现在树莓派已经出了第四代了,可以去这里购买:传送门
双盘位的硬盘盒:传送门
安装 Nextcloud 前的准备
确保树莓派已经烧录好系统,可参考:《树莓派(Raspberry Pi)入门实战记录之 SSH 局域网无线连接》为树莓派烧录系统并设置 SSH 连接。
创建目录、用户
- 创建 nobody 用户组,统一系统用户,避免出现权限问题
$ sudo groupadd nobody
- 创建网站服务根目录
$ sudo mkdir [path]/web
树莓派硬盘挂载
- 树莓派开启支持 exfat
$ sudo apt-get install exfat-utils
$ sudo reboot now // 重启生效
- 连接硬盘,查看硬盘信息
$ sudo fdisk -l
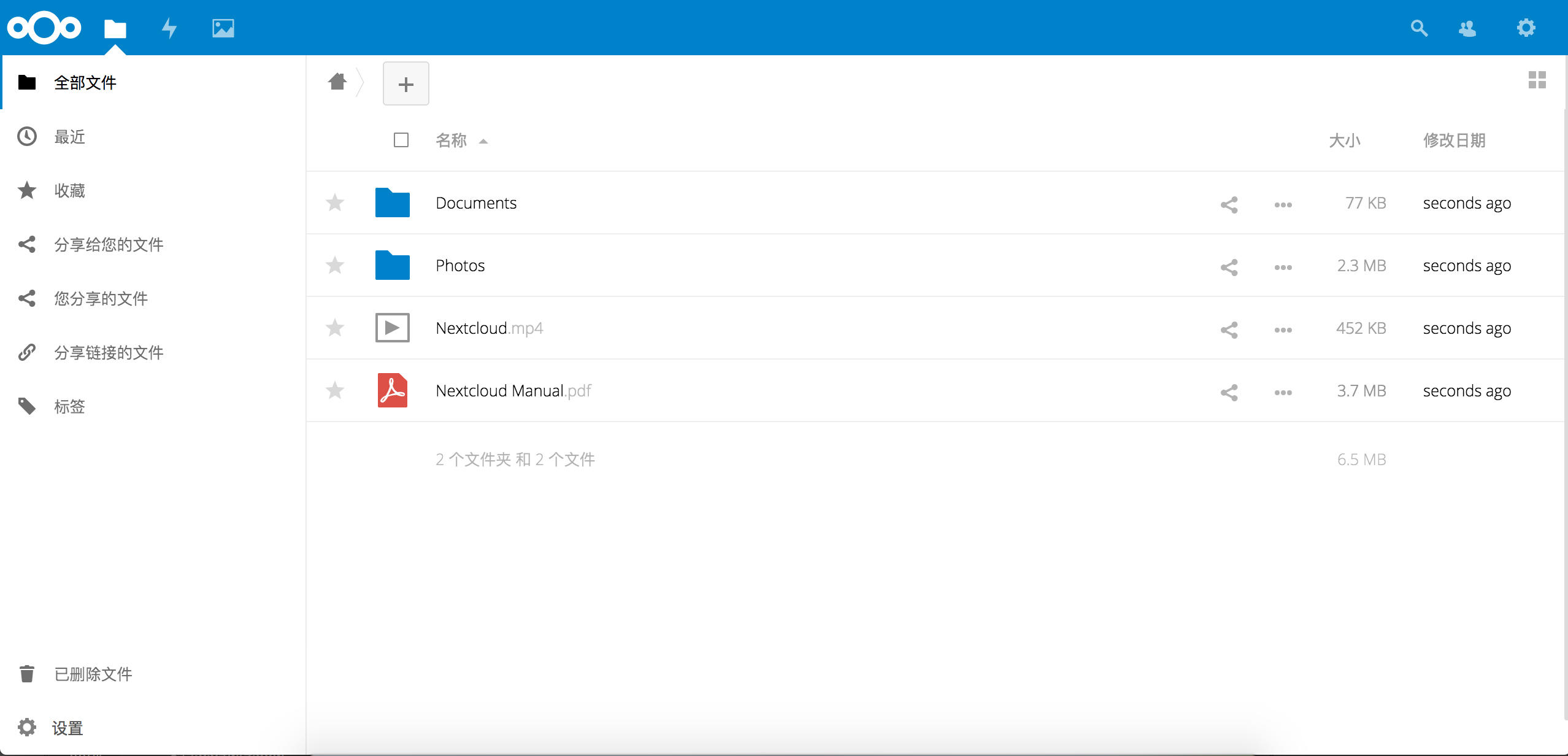
我的硬盘信息显示如下:
所以,挂载路径为:/dev/sda
3. 格式化硬盘为 ext4 格式
$ sudo mkfs.ext4 /dev/sda
- 创建硬盘挂载点
$ mkdir [path]/disk
- 挂载硬盘
$ sudo mount -t ext4 /dev/sda [path]/disk
- 设置开机自动挂载
编辑/etc/fstab,加入以下配置:
/dev/sda [path]/disk ext4 defaults 0 0
安装 MariaDB
- 使用 apt-get 安装 MariaDB
$ sudo apt-get install mariadb-server
- 创建数据库
$ mysql -uroot -p
$ mysql> CREATE DATABASE nextcloud CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
- 创建 nobody 用户并授权
$ mysql> CREATE USER 'nobody'@'%' IDENTIFIED BY '[password]';
$ mysql> GRANT ALL ON nextcloud.* TO 'nobody'@'%';
- 为 Nextcloud 配置 MariaDB,参考:Database Requirements for MySQL / MariaDB
$ mysql> SET GLOBAL binlog_format = 'MIXED';
[mysqld]
- 配置 innodb ——
/etc/mysql/my.cnf,加入以下配置:- 设置 binlog_format
innodb_large_prefix=on
innodb_file_format=barracuda
innodb_file_per_table=1
“`
安装 openresty(nginx) 设置随系统启动
- 上传 openresty
scp [local-path]/openresty-1.11.2.3.tar.gz pi@[ip-address]:[path]/openresty-1.11.2.3.tar.gz
- 编译安装 openresty
$ sudo apt-get install libpcre3 libpcre3-dev libssl-dev
$ ./configure --with-luajit --with-pcre
$ make
$ sudo make install
- 部署 Nginx 站点配置
- 部署 openresty 开机自启动
编译安装 php7.1
- 编译安装
$ sudo apt-get install libxml2-dev curl libcurl4-gnutls-dev libjpeg-dev libxslt-dev
$ ./configure --prefix=[path]/php \
--with-openssl \
--with-curl \
--with-freetype-dir \
--with-gd \
--with-gettext \
--with-iconv-dir \
--with-kerberos \
--with-libdir=lib64 \
--with-libxml-dir \
--with-mysqli \
--with-pcre-regex \
--with-pdo-mysql \
--with-pdo-sqlite \
--with-pear \
--with-jpeg-dir \
--with-png-dir \
--with-xmlrpc \
--with-xsl \
--with-zlib \
--with-regex \
--enable-ctype \
--enable-maintainer-zts \
--enable-fpm \
--enable-bcmath \
--enable-libxml \
--enable-inline-optimization \
--enable-gd-native-ttf \
--enable-mbregex \
--enable-mbstring \
--enable-opcache \
--enable-pcntl \
--enable-shmop \
--enable-soap \
--enable-sockets \
--enable-sysvsem \
--enable-xml \
--enable-zip
$ make
$ sudo make install
- 部署 php 配置文件
$ sudo cp [php-source-code-path]/php.ini-production [php-path]/php/lib/php.ini
$ sudo cp [php-path]/php/etc/php-fpm.conf.default [php-path]/php/etc/php-fpm.conf
$ sudo cp [php-path]/php/etc/php-fpm.d/www.conf.default [php-path]/php/etc/php-fpm.d/www.conf
- 编辑
[php-path]/php/etc/php-fpm.d/[www.conf](http://www.conf),加入以下 PATH(通过执行$ printenv PATH获得)
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/local/games:/usr/games
- 继续编辑
[php-path]/php/etc/php-fpm.d/[www.conf](http://www.conf),启动 socket 连接方式(提升系统执行效率)
listen= /var/run/php71-fpm.sock
listen.owner = nobody
listen.group = nobody
- 配置 php-fpm 随系统启动
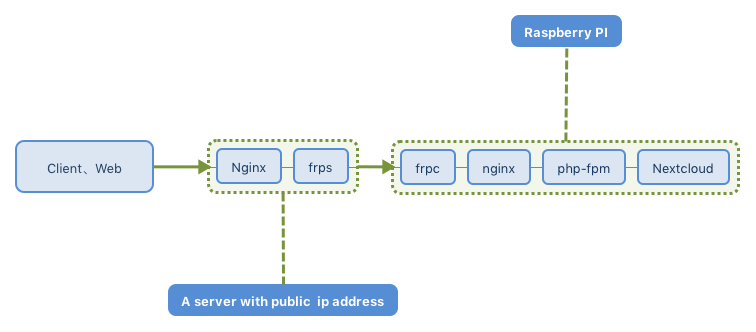
安装 Nextcloud 的准备工作完成,下一步是使用 frp 实现内网穿透搭建 Nextcloud 私有云。






 凭据选择刚才添加的那个,这里是 github。保存配置,凭据添加完成。
凭据选择刚才添加的那个,这里是 github。保存配置,凭据添加完成。