
当前的浏览器现状
当前主流浏览器使用的内核包括 Webkit(Safari、Chrome、Opera等),Trident(IE),Gecko(Firefox)等,其中最值得了解的当然是 Webkit。
Webkit 是由苹果公司开发的,供自家浏览器 Safari 使用的内核。Safari 于2003年1月7日首次发行测试版。2010年4月,苹果公司宣布了其浏览器引擎的最新项目 Webkit2。Webkit 内核实际上包含 WebCore 渲染引擎和 JavaScriptCore javascript 引擎。
Chrome 浏览器自2008年发行起,一直使用 Webkit 作为其内核原型。在13年发布的 Chrome 28.0.1469.0 版本中,又改为使用 Blink 内核。
前面说过,Webkit 内核包含 WebCore 渲染引擎和 JavaScriptCore javascript 引擎。Chrome 中使用的 javascript 引擎实际上是自家开发的大名鼎鼎的 V8 引擎,V8 主要用在 Chromium 和 Chrome 浏览器中。因此,Chrome 中的 Webkit 和 Safari 中的 Webkit 并不等价,而从 Blink 内核开始,其差别越来越大。
Chromium 和 Chrome 使用同样的内核,Chromium 是开源的,Chrome 是闭源的,许多功能会在 Chromium 浏览器上应用,稳定后才会在 Chrome 上推出。大多国产浏览器实际上是基于 Chromium 而不是 Webkit 开发的,因此会称 Chromium 为内核。
移动设备上,Android 4.4 之前的浏览器默认使用 Webkit 内核,Android 4.4 以及之后使用 Chromium 内核。
鉴于上述,本文技术方面的介绍,是在 Chromium 层面的。
从资源加载过程来优化站点
网页是如何展现在我们面前的
从输入 URL 开始,到网页展现在我们面前,浏览器主要做了以下几件事件:
- 从网页的 URL 加载资源
- 构建 DOM 树
- 从 DOM 树构建 Webkit 的绘图上下文
- 从绘图上下文生成最终的图像
当然,每一步都进行了复杂的处理。而且,浏览器一般会同时做这些事情。下面从网页开发者角度说明每一步中值得关注的点。
从网页 URL 到加载资源的过程
通过 URL 打开一个网站,无论这个网站是静态的还是动态的,浏览器通过这个 URL 识别到的都应该是一个 html 文档资源。然后浏览器通过解析这个 html 文档,通过标签识别文档中的其他资源,进一步加载其他资源。
资源加载和缓存
Chromium 使用多进程的资源加载和缓存机制。其中 Renderer 进程并没有请求资源的权限,当浏览器需要请求资源的时候,会交给 Browser 进程处理,Browser 进程处理完毕后再交给 Renderer 进程渲染页面。Browser 进程和 Renderer 进程通过进程间通信的方式传递数据。
如果每次请求资源都从远程服务器请求,将会非常耗时和浪费资源,Chromium 采用了高效的缓存机制。需要请求资源的时候,会先去缓存查找资源是否已经存在,不存在时才会去请求网络资源。
DNS 预取和 TCP 预连接
在请求网络资源的时候,会经过域名解析和 TCP 连接过程,Chromium 针对这两个过程,分别做了优化。当我们在浏览网页的时候,Chromium 会提取网页中的超链接,利用系统的 DNS 机制预解析,并将解析结果保存下来,当我们点击链接的时候,就不需要进行 DNS 解析了。开发者可以显式声明哪些域名需要提前解析,做法如下:
当我们在浏览器地址栏输入网址的时候,如果输入的网址和候选项匹配,那么 Chromium 也会预解析该域名。DNS 预取机制大概可以节省 60ms – 120ms 或者更长的时间。
更进一步,Chromium 甚至会在 DNS 解析之后,用户点击链接之前提前建立 TCP 连接。这里,Chromium 会使用追踪技术预测我们可能点击的链接,在有很大把握的时候才会做这些事情。
对于网页开发者的启示:
- 减少网页的重定向,以更好地应用浏览器的 DNS 预取技术
- 适当地合并资源,减少浏览器建立连接的次数
- 压缩资源,节省数据量和数据传输时间
在 Chromium 或者 Chrome 浏览器中,我们可以通过chrome://net-internals/#dns来查看 DNS 缓存情况,并可以通过 Clear cache 和 Flush sockets 工具来及时清除 DNS 缓存数据。在开发过程中,在切换域名 host 之后,用此工具可以使网页立即解析到新的地址,而不用重启浏览器。
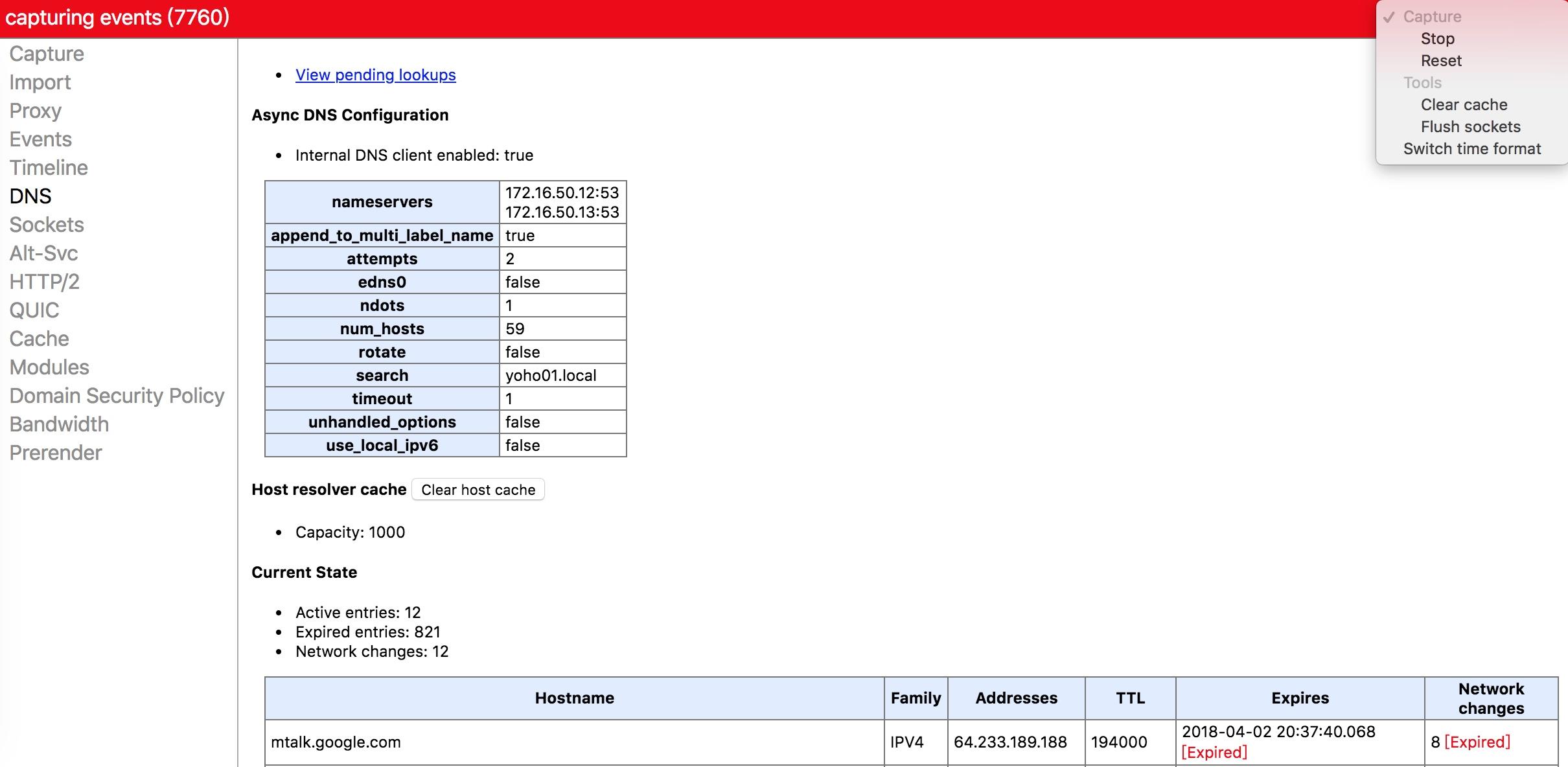
net-internals 工具中的 DNS 面板截图
从 html 文档构建 DOM 树的过程优化站点
构建 DOM 树与资源加载
上面介绍了浏览器加载资源的过程,在这个过程中,浏览器还会同时进行 DOM 树的构建工作,甚至下文要介绍的构建 Webkit 绘图上下文的工作也是同步进行的,要不然页面呈现在我们面前就太慢了。
对于图片、CSS、视频等文件,浏览器从 HTML 代码解析到他们的 URL 的时候,会通过相关的资源管理器异步加载,这不会阻碍浏览器构建 DOM 树,但是 JavaScript 代码除外。当浏览器解析到 JavaScript 代码节点或者 JavaScript 资源的 URL,会停下 DOM 树的构建,去加载 JavaScript 文件,执行 JavaScript 代码,然后再继续构建 DOM 树。所以,我们要特别注意,当用 JavaScript 去操作 DOM 的时候,DOM 树很可能还没有构建完成,此时 JavaScript 是获取不到 DOM 节点的。总结 JavaScript 代码出现在文档中时会出现的具体问题:
1\. 中止 DOM 树的构建;
2\. 不会并发下载接下来文档中可能存在的 src 资源,比如图片;
3\. JavaScript 代码如果涉及到对 DOM 的读写,可能会失败;
4\. JavaScript 代码的执行耗费时间,延长文档的加载完成时间。
针对上述问题,关注两个 JavaScript 事件:onload 和 DOMContentLoaded。顺便说明,支持 onload 事件的 JavaScript 对象有 image, layer, window,经常谈到的是window.onload。window.onload事件是在包括图像等资源在内的,整个页面全部加载完成之后才会触发,DOMContentLoaded事件在网页文档加载并解析完毕(DOM 树构建完成)之后就会触发。所以,对 DOM 的操作放在DOMContentLoaded事件触发之后最好。将 JavaScript 代码放在文档的最后(一般是置于 body 元素里面紧贴 body 闭合标签)也是一种方案。
当然,确实有一些 JavaScript 代码是与 DOM 无关的。这种情况下,可以为 script 元素添加async属性,告诉浏览器这是可以异步执行的 JavaScript 代码。
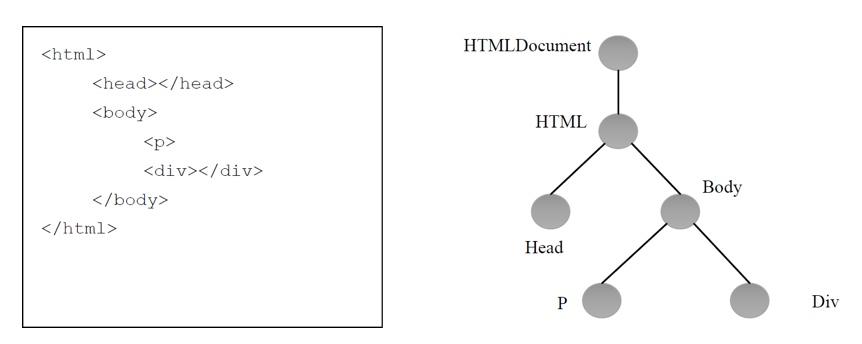
HTML 网页和它的 DOM 表示
Webkit 实际上具有预扫描和预加载机制,在文档中解析到 JavaScript 代码的时候,会继续解析后面的文档查看有没有资源需要下载,有的话就下载,但在实际测试中,浏览器确实去下载资源了,但是由于 JavaScript 代码执行时的阻塞,资源并没有加载。而且其他的浏览器中不一定有此机制。因此,还是推荐使用前面的处理策略。
发表回复