
Paddlehub 是百度飞浆推出的预训练模型管理工具,Paddlehub 提供对预训练模型的安装、卸载、升级、部署等功能。
Sagemaker 是 AWS 推出的机器学习工具平台,集成了 Jupyter Notebook,通过 Sagemaker WEB 工具或者 SDK 可快速完成机器学习相关的模型训练、部署等过程。
在 Sagemaker 上面部署自己的机器学习模型分为以下几个步骤:
- 将服务封装成成符合 Sagemaker 要求的镜像托管到 AWS ECR 容器仓库;
- 在 Sagemaker 上将镜像制作成 Sagemaker 定义的模型;
- 创建终端节点配置,部署终端节点。
其中,第一步是比较繁琐的,要按照 Sagemaker 平台的要求来合理规划代码及数据在 Docker 镜像中的路径。2、3步都可以通过 Sagemaker 的 WEB 界面完成。
将服务封装成成符合 Sagemaker 要求的镜像托管到 AWS ECR 容器仓库
Sagemaker 约定了推理模型的容器必须实施在端口 8080 上响应 /invocations 和 /ping 的 Web 服务器。也就是说推理模型必须部署一个端口为 8080 的 Web 服务,这个服务需要有两个 API:一个是 http://localhost:8080/invocations 用来接收数据,返回推理结果;一个是 http://localhost:8080/ping 用来响应健康检查。
Paddlehub 提供了启动推理服务的快速命令:
hub serving start -m chinese_ocr_db_crnn_mobile -p 8866其中,-p 参数用来指定端口,这里保持使用 8866 端口号。计划在镜像里面加一个 Nginx 的 server 配置,用来响应 8080 端口上 path 为/invocations 的推理请求,将请求转发到 Paddlehub 服务 的 8866 端口上,并添加另外一个 server 配置,响应 8080 端口上 path 为 /ping 的请求,来通过 Sagemaker 的健康检查。
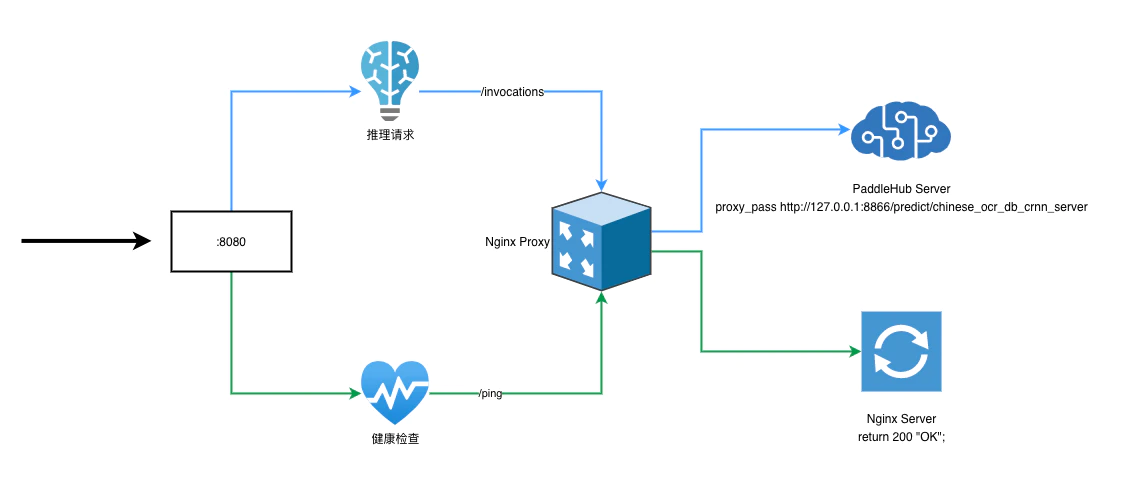
基础镜像基于 ubuntu docker 基础镜像制作。
docker run -it ubuntu /bin/bash
apt-get update安装 nginx 并配置
apt-get install nginx将准备好的 Nginx 配置文件上传到 docker 镜像中:
docker cp /home/ec2-user/SageMaker/ocr/ocr.conf [启动的容器ID]:/etc/nginx/conf.d/ocr.confNginx 配置参考:
server {
listen 8080;
server_name localhost;
proxy_set_header X-Real_IP $remote_addr;
proxy_set_header Host $host;
proxy_set_header X_Forward_For $proxy_add_x_forwarded_for;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection 'upgrade';
location /ping {
add_header Access-Control-Allow-Origin * always;
add_header Access-Control-Allow-Headers X-Requested-With;
add_header Access-Control-Allow-Methods PUT,POST,GET,DELETE,OPTIONS;
return 200 "OK";
}
location /invocations {
add_header Access-Control-Allow-Origin * always;
add_header Access-Control-Allow-Headers X-Requested-With;
add_header Access-Control-Allow-Methods PUT,POST,GET,DELETE,OPTIONS;
proxy_pass http://127.0.0.1:8866/predict/chinese_ocr_db_crnn_server;
}
}
安装 python 3.6,移除默认的 python 3.8
ubuntu 镜像中可能存在 python3.8 版本, 在我安装的时候,Paddlehub 在 python3.8 下运行会出现问题。
apt-get install software-properties-common
add-apt-repository ppa:deadsnakes/ppa
apt-get update
apt-get install python3.6
apt-get purge remove python3.8
echo alias python=python3 >> ~/.bashrc
echo alias python3=python3.6 >> ~/.bashrc
source ~/.bashrc安装 PaddlePaddle、PaddleHub
apt-get install python3-pip
echo alias pip=pip3>> ~/.bashrc
source ~/.bashrc
pip install paddlepaddle-gpu==2.0.0rc
pip install paddlehub==2.0.0b安装 OCR 文字识别模型
apt-get install git libgl1-mesa-glx
pip install sentencepiece shapely pyclipper
hub install chinese_ocr_db_crnn_mobile==1.1.1将准备好的启动脚本上传到正在编辑的容器中
这里有两个,一个是供 CPU 实例类型用的,一个是供 GPU 实例类型用的。
docker cp /home/ec2-user/SageMaker/ocr/run-gpu.sh [启动的容器ID]:/root/run.sh # 或者
docker cp /home/ec2-user/SageMaker/ocr/run.sh [启动的容器ID]:/root/run.shrun 脚本参考:
#!/bin/bash
# nginx
/usr/sbin/nginx > /var/log/nginx.log 2>&1 &
# ocr service
hub serving start -m chinese_ocr_db_crnn_server --use_gpu > /var/log/chinese_ocr_db_crnn_server.log 2>&1 & # For gpu
# hub serving start -m chinese_ocr_db_crnn_server > /var/log/chinese_ocr_db_crnn_server.log 2>&1 & # For cpu
# just keep this script running
while [[ true ]]; do
sleep 1
done打包上传基础镜像到 AWS ECR
docker commit -m "[note]" -a "19050023" [启动的容器ID] [镜像名称]:[base-version]
docker tag [镜像名称]:[base-version] [AWS ECR 地址].amazonaws.com.cn/[镜像名称]:[base-version]
docker push [AWS ECR 地址].amazonaws.com.cn/[镜像名称]:[base-version]Dockerfile 配置参考:
# FROM [镜像名称]:v1
FROM [镜像名称]:v1-gpu
# COPY run.sh /root/run.sh # For cpu
COPY run-gpu.sh /root/run.sh # For gpu
RUN chmod +x /root/run.sh
ENTRYPOINT ["/root/run.sh"]
EXPOSE 8080在 Sagemaker 上将镜像制作成 Sagemaker 定义的模型

选择“创建模型”,进入创建模型的配置页面
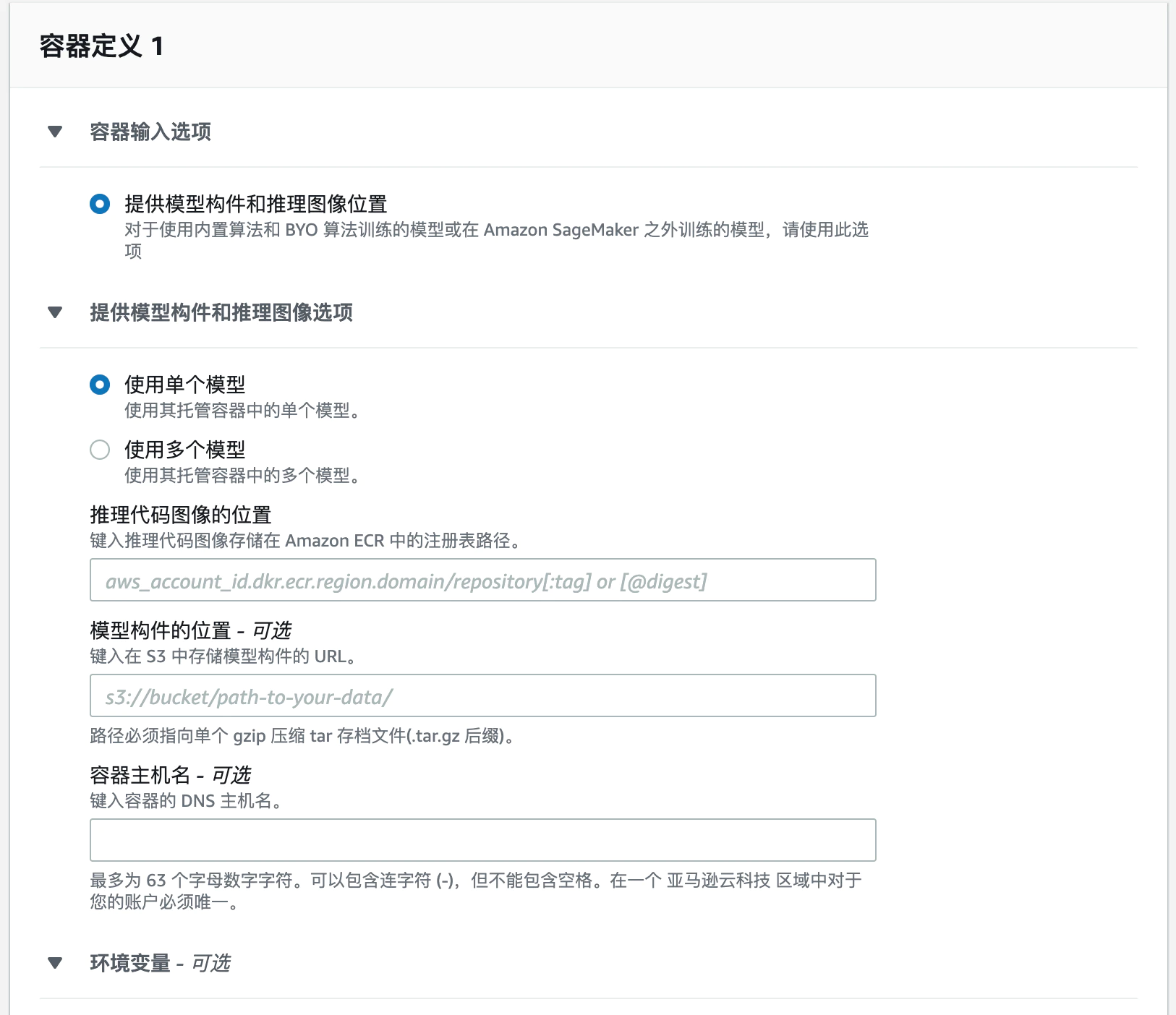
推理代码图像位置一栏填上面步骤中上传的推理镜像的 ECR 地址,模型构件指预训练模型等,可以上传到 s3 存储,SageMaker 运行的时候会拉去模型数据,解压到指定的目录中,这里不需要。完成配置,点“创建模型”即可。
创建终端节点,部署终端节点
在 SageMaker 终端节点模块选择创建终端节点
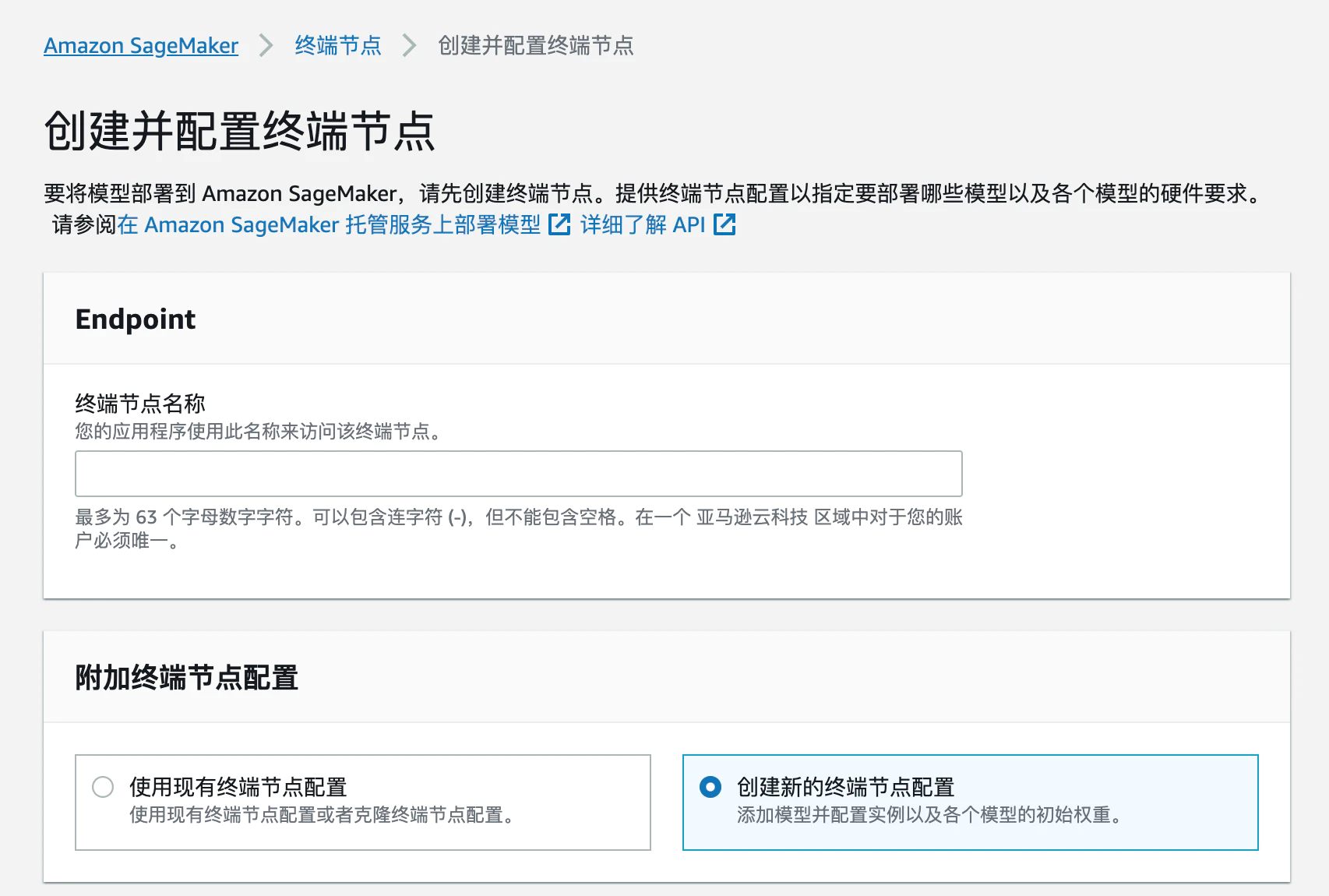
创建新的终端节点配置,添加模型,并调整实例类型
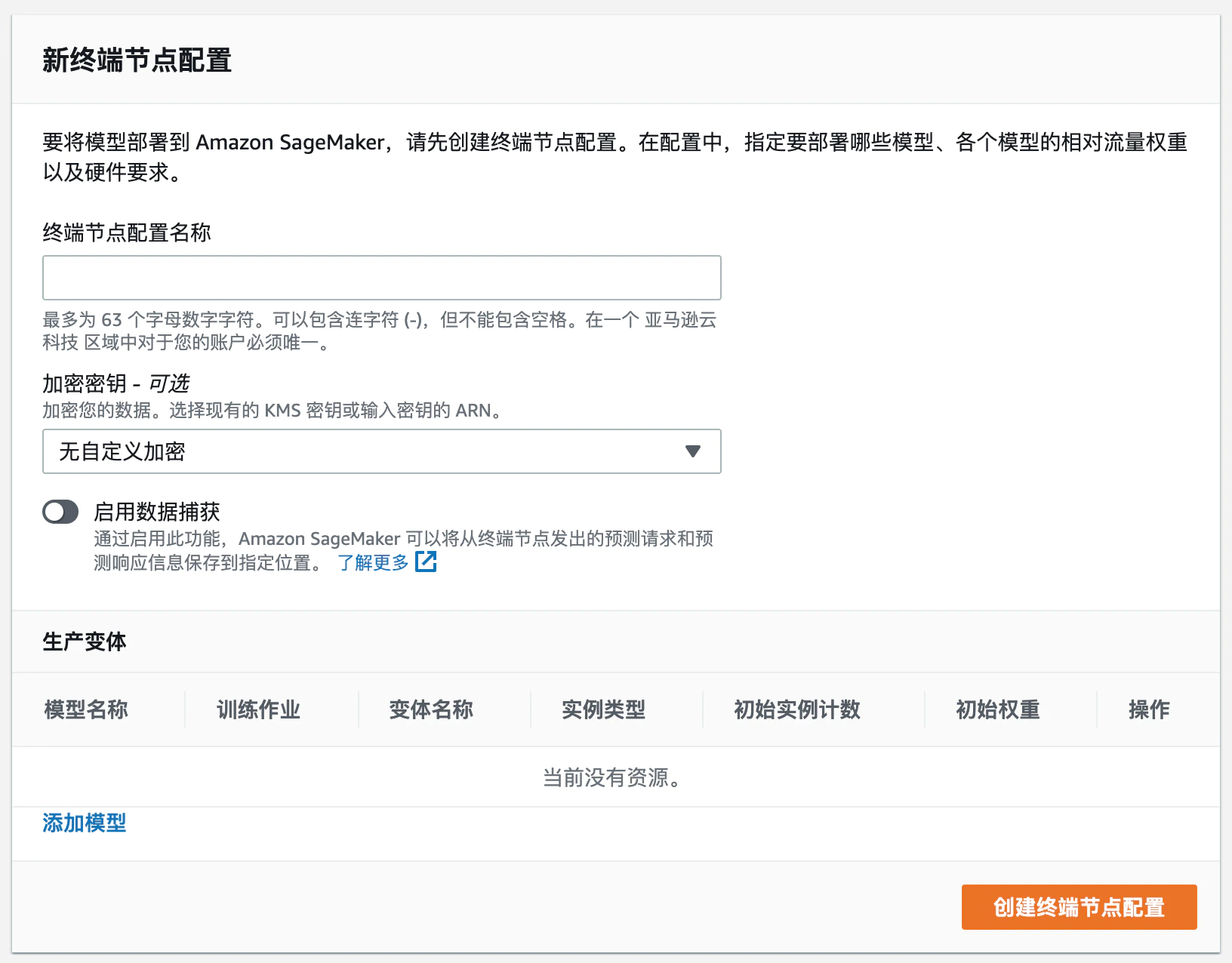
点击 创建终端节点配置 即创建好了配置文件。
最后,点击页面底部的“创建终端节点”,服务就部署好了。